Dask

Cet exemple présente les concepts de DASK; il est issu de travaux pratiques (TP) présentés lors d'un atelier technique du pôle Océan ODATIS, en mars 2021, pendant lequel les participants pouvaient exécuter chaque cellule du notebook. Pour exemple, nous donnons accès à ce même notebook au format pdf et au format ipynb, applicable dans un Jupyter notebook.
Les libellés des principales étapes du TP sont reportées ci-dessous et accessibles directement via le lien pdf.
Dask est une bibliothèque de calcul parallèle flexible pour le calcul analytique. Dask fournit un ordonnancement dynamique des tâches parallèles et des collections de données volumineuses de haut niveau comme dask.array et dask.dataframe.
- Démarrer un cluster distribué Dask et un client pour le tableau de bord (pdf)
- Dask Arrays (pdf). Un tableau dask ressemble beaucoup à un tableau numpy. Cependant, un tableau dask ne contient pas directement de données. Il représente plutôt symboliquement les calculs nécessaires pour générer les données. Rien n'est réellement calculé tant que les valeurs numériques réelles ne sont pas nécessaires. Ce mode de fonctionnement est appelé "paresseux" ; il permet d'effectuer des calculs complexes et volumineux de manière symbolique avant de les transférer au programmateur pour exécution.
- dask.delayed (pdf) est un moyen simple et puissant de paralléliser le code existant.
- Annoter les fonctions avec dask.delayed pour les rendre paresseuses (pdf)
- Soumettre des appels de fonction au cluster : appels de fonction individuels avec la méthode client.submit ou de nombreux appels de fonction avec la méthode client.map (pdf)
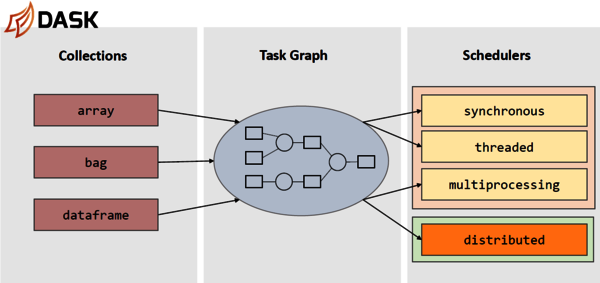
- Dask Schedulers (pdf) Les ordonnanceurs orchestrent les tâches dans les graphes de calcul afin qu'elles puissent être exécutées en parallèle. Trois ordonnanceurs locaux et un ordonnanceur distribué (dask.distributed).
- Dask Distributed (pdf). Dask peut être déployé sur une infrastructure distribuée, comme un système HPC ou un système de cloudcomputing.
- Dask Jobqueue (pdf)
- Dask Kubernetes (pdf)